In this article we study two different ways of handling client requests that involve a blocking operation: multithreading programming through concurrent queues and asynchronous network calls through distributed systems.
The Problem
We have clients connected to a HTTP server (or any TCP server) sending requests that require a heavy computation, in other words, each request needs to execute some code that can take an arbitrary amount of time to complete. If we isolate this time-consuming code in a function, we can then call this function a blocking call. Simple examples would be a function that queries a database or a function that manipulates a large image file.
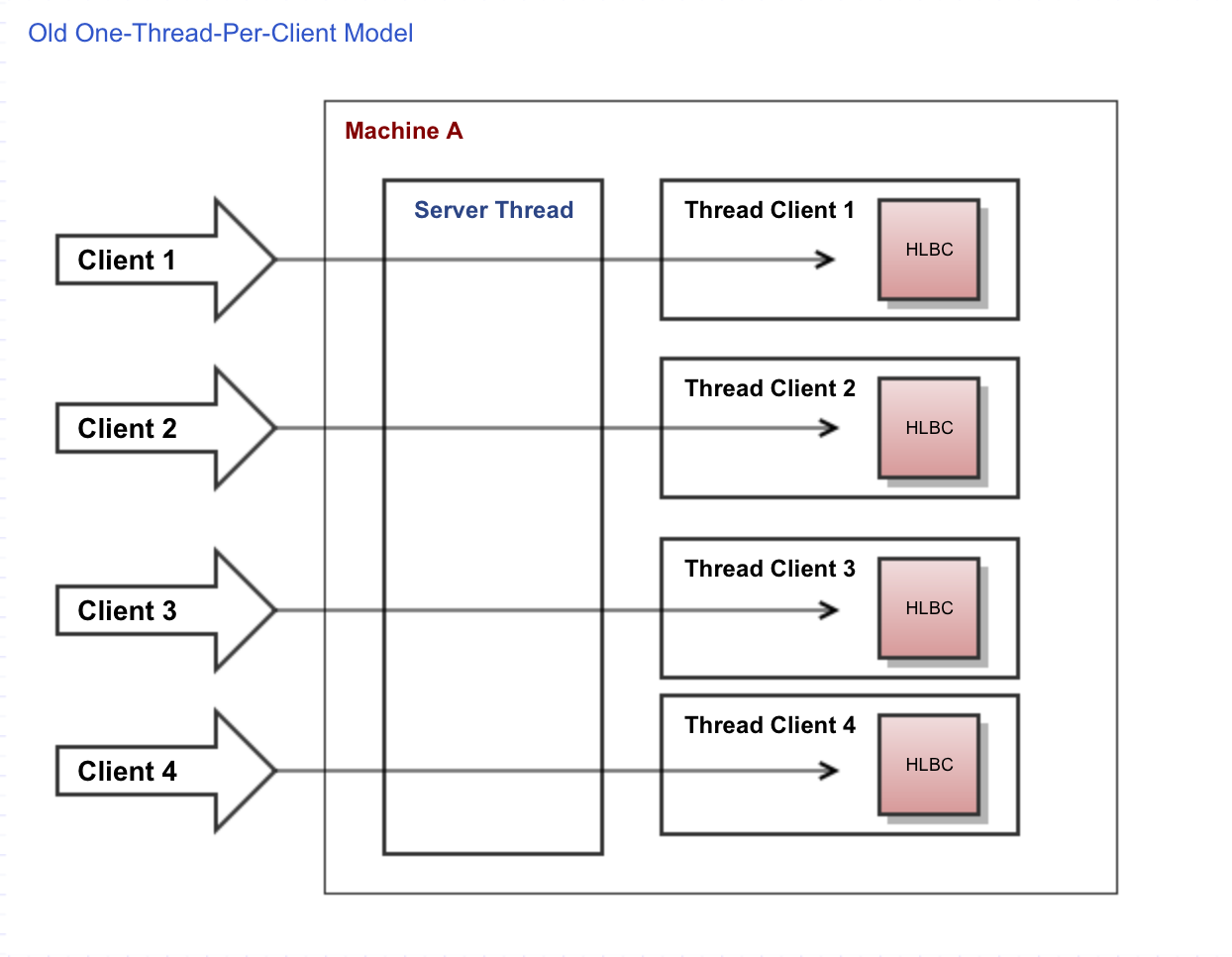
In the old model where one connection would be handled by its own dedicated thread, there would be no problem. But in the new reactor model where a single thread will be handling thousands of connections, all it takes is a single connection executing a blocking call to impact and block all other connections. When you have a single-threaded system, the worst thing that can happen is blocking your critical thread. How do we solve this problem without reverting back to the old one-thread-per-connection model?
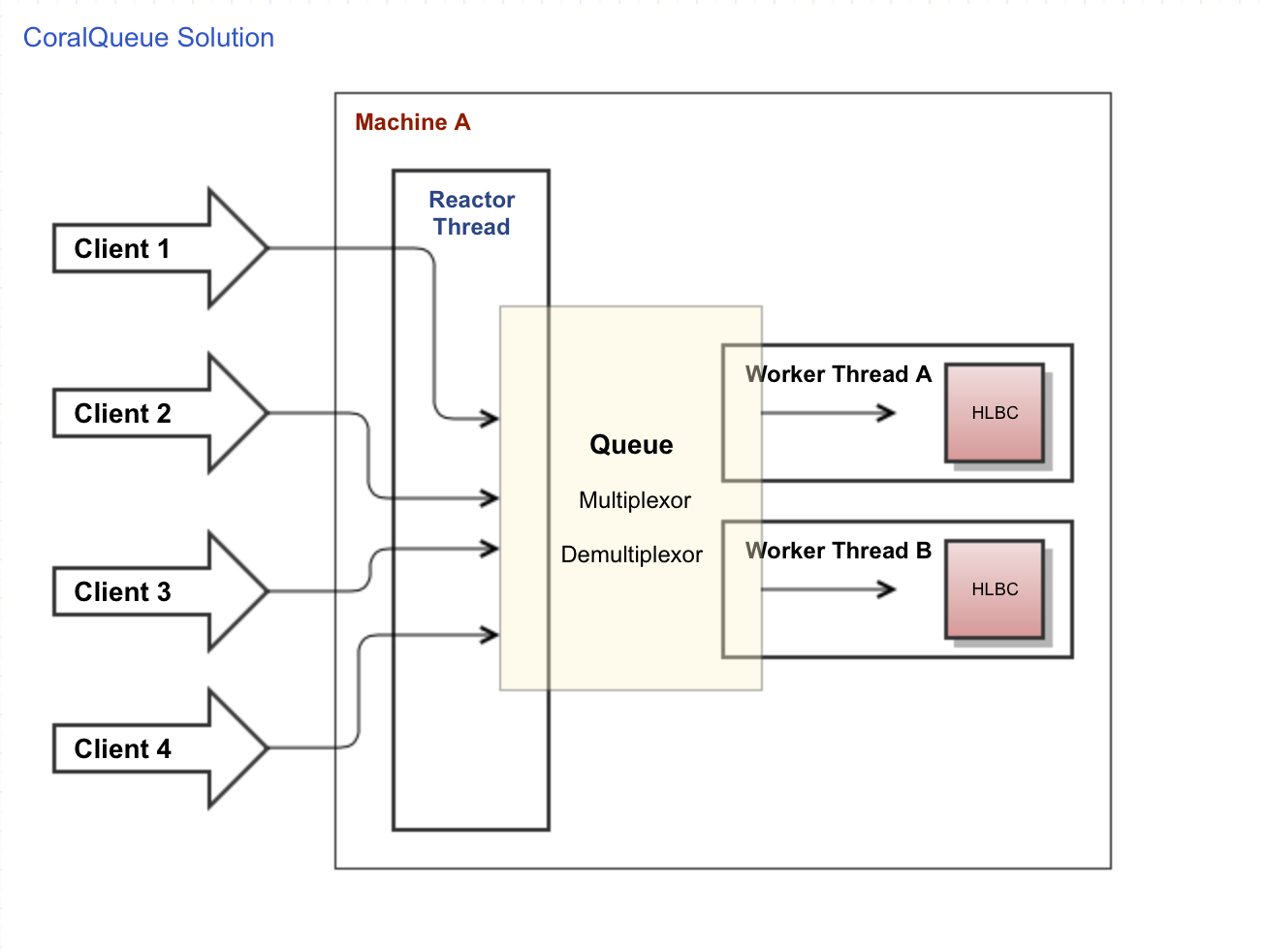
Solution #1: Thread Concurrency
The first solution is described in detail in this article. You basically use CoralQueue to distribute the requests’ work (not the requests themselves) to a fixed number of threads that will execute them concurrently (i.e. in parallel). Let’s say you have 1000 simultaneous connections. Instead of having 1000 simultaneous threads (i.e. the impractical one-thread-per-connection model) you can analyze how many available CPU cores your machine has and choose a much smaller number of threads, let’s say 4. This architecture will give you the following advantages:
- The critical reactor thread handling the http server requests will never block because the work necessary for each request will be simply added to a queue, freeing the reactor thread to handle additional incoming http requests.
- Even if a thread or two get a request that takes a long time to complete, the other threads can continue to drain the requests sitting on the queue.
If you can guess in advance which requests will take a long time to execute, you can even partition the queue in lanes and have a fast-track lane for high-priority / fast requests, so they always find a free thread to execute.
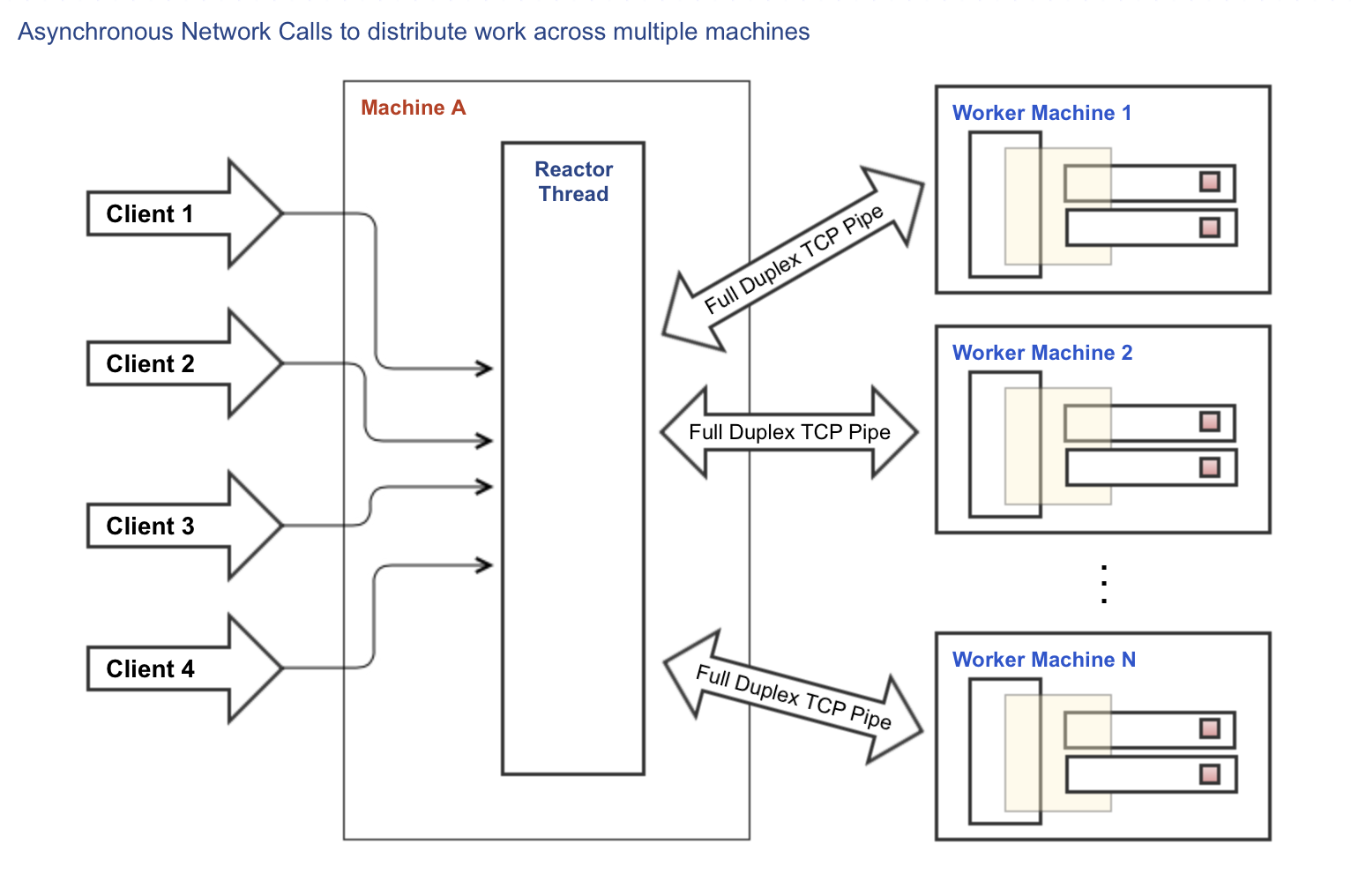
Solution #2: Distributed Systems
Instead of doing everything on a single machine, with limited CPU cores, you can use a distributed system architecture and take advantage of asynchronous network calls. That simplifies the http server handling the requests, which now does not need any additional threads and concurrent queues. It can do everything on a single, non-blocking reactor thread. It works like this:
- Instead of doing the heavy computation on the http server itself, you can move this task to another machine (i.e. node).
- Instead of distributing work across threads using CoralQueue, you can simply make an asynchronous network call and pass the work to another node responsible for the heavy computation task.
- The http server will asynchronously wait for the response from the heavy computation node. The response can take as long as necessary to arrive through the network because the http server will never block.
- The http server can use only one thread to handle incoming http connection from external clients and outgoing tcp connections to the internal nodes doing the heavy computation work.
- And the beauty of it is that you can scale by simply adding/removing nodes as necessary. Dynamic load balancing becomes trivial.
- Failover is not that hard either: If one node fails, the clients waiting on that node can re-send their work to another node.
Now you might ask: How do we implement the architecture for this new node responsible for the heavy computation work? Aren’t we just transferring the problem from one machine to another? Yes but with one important difference: now you can add and remove nodes dynamically, as needed. Before you were stuck with the number of available CPU cores in your single machine. It is also important to note that the http server does not care or need to know how the nodes will choose to implement the heavy computation task. All it needs to do is send the asynchronous requests. As far as the http server is concerned, the heavy computation node can use the best or the worst architecture to do its job. The server will make a request and wait asynchronously for the answer.
An Example
Let’s say we have an http server that receives requests from clients for stock prices. The way it knows the price of a stock is by making an http request to GoogleFinance to discover the price. If making a request to Google is a blocking call (and it is because how can you know in advance how long it is going to take to get a response?) we can use Solution #1. Requests will be distributed across threads that will process them in parallel, blocking if necessary to wait for Google to respond with a price. But wait a minute, why can’t we just treat Google as a separate node in our distributed system and make an asynchronous call to its http servers? That’s Solution #2 and the code bellow shows how it can be implemented:
/*
* Copyright (c) CoralBlocks LLC (c) 2017
*/
package com.coralblocks.coralreactor.client.bench.google;
import java.nio.ByteBuffer;
import java.util.Iterator;
import com.coralblocks.coralbits.ds.IdentityMap;
import com.coralblocks.coralbits.ds.PooledLinkedList;
import com.coralblocks.coralbits.util.ByteBufferUtils;
import com.coralblocks.coralreactor.client.Client;
import com.coralblocks.coralreactor.nio.NioReactor;
import com.coralblocks.coralreactor.server.Server;
import com.coralblocks.coralreactor.server.http.HttpServer;
import com.coralblocks.coralreactor.util.Configuration;
import com.coralblocks.coralreactor.util.MapConfiguration;
public class AsyncHttpServer extends HttpServer implements GoogleFinanceListener {
public class AsyncHttpAttachment extends HttpAttachment {
// store the symbol requested by each client so we can re-send during failover...
StringBuilder symbol = new StringBuilder(32);
@Override
public void reset(long clientId, Client client) {
super.reset(clientId, client);
symbol.setLength(0); // start with a fresh empty one...
}
}
// number of http clients used to connect to google
private final int connectionsToGoogle;
// the clients used to connect to google
private final GoogleFinanceClient[] googleClients;
// a list of clients waiting for responses from google (for each google http connection)
private final IdentityMap<GoogleFinanceClient, PooledLinkedList<Client>> pendingRequests;
private final StringBuilder symbol = new StringBuilder(32);
private final StringBuilder price = new StringBuilder(32);
public AsyncHttpServer(NioReactor nio, int port, Configuration config) {
super(nio, port, config);
this.connectionsToGoogle = config.getInt("connectionsToGoogle");
this.googleClients = new GoogleFinanceClient[connectionsToGoogle];
this.pendingRequests = new IdentityMap<GoogleFinanceClient, PooledLinkedList<Client>>(connectionsToGoogle);
MapConfiguration googleFinanceConfig = new MapConfiguration();
googleFinanceConfig.add("readBufferSize", 512 * 1024); // the html page returned is big...
for(int i = 0; i < googleClients.length; i++) {
googleClients[i] = new GoogleFinanceClient(nio, "www.google.com", 80, googleFinanceConfig);
googleClients[i].addListener(this);
googleClients[i].open();
pendingRequests.put(googleClients[i], new PooledLinkedList<Client>());
}
}
@Override
protected Attachment createAttachment() {
return new AsyncHttpAttachment(); // let's use our attachment
}
private CharSequence parseSymbolFromClientRequest(ByteBuffer request) {
// for simplicity we assume that the symbol is the request
// Ex: GET /GOOG HTTP/1.1 => the symbol is GOOG
int pos = ByteBufferUtils.positionOf(request, '/');
if (pos == -1) return null;
request.position(pos + 1);
pos = ByteBufferUtils.positionOf(request, ' ');
if (pos == -1) return null;
request.limit(pos);
symbol.setLength(0);
ByteBufferUtils.parseString(request, symbol); // read from ByteBuffer to StringBuilder
return symbol;
}
private GoogleFinanceClient chooseGoogleClient(long clientId) {
// try as much as you can to get a google client...
// that's because some connections might be dead
for(int i = 0; i < connectionsToGoogle; i++) {
int index = (int) ((clientId + i) % connectionsToGoogle);
GoogleFinanceClient googleClient = googleClients[index];
if (googleClient.isConnectionOpen()) return googleClient;
}
return null;
}
@Override
protected void handleMessage(Client client, ByteBuffer msg) {
AsyncHttpAttachment a = (AsyncHttpAttachment) getAttachment(client);
ByteBuffer request = a.getRequest();
CharSequence symbol = parseSymbolFromClientRequest(request);
if (symbol == null) {
System.err.println("Bad request from client: " + client);
return;
}
a.symbol.setLength(0);
a.symbol.append(symbol);
sendToGoogle(client, symbol);
}
private void sendToGoogle(Client client, CharSequence symbol) {
long clientId = getClientId(client);
// distribute requests across our Google http clients...
GoogleFinanceClient googleClient = chooseGoogleClient(clientId);
if (googleClient == null) {
System.err.println("It looks like all google clients are dead! Dropping request from client: " + client);
return;
}
// send the request to google (it fully supports http pipelining)
googleClient.sendPriceRequest(symbol);
// add this client to the line of clients waiting for a response from the google http client
pendingRequests.get(googleClient).add(client);
}
@Override // from GoogleFinanceListener interface
public void onSymbolPrice(GoogleFinanceClient googleClient, CharSequence symbol, ByteBuffer priceBuffer) {
// Got a response from google, respond to the client waiting for the price...
PooledLinkedList<Client> clients = pendingRequests.get(googleClient);
Client client = clients.removeFirst();
price.setLength(0);
ByteBufferUtils.parseString(priceBuffer, price);
CharSequence response = getHttpResponse(price);
client.send(response);
}
@Override // from GoogleFinanceListener interface
public void onConnectionOpened(GoogleFinanceClient client) {
// NOOP
}
@Override // from GoogleFinanceListener interface
public void onConnectionTerminated(GoogleFinanceClient googleClient) {
// Our connection to google was broken...
// failover all clients waiting on this google connection by re-sending them to another google connection
PooledLinkedList<Client> clients = pendingRequests.get(googleClient);
Iterator<Client> iter = clients.iterator();
while(iter.hasNext()) {
Client c = iter.next();
AsyncHttpAttachment a = (AsyncHttpAttachment) getAttachment(c);
if (a.symbol.length() > 0) {
sendToGoogle(c, a.symbol); // re-send
}
}
clients.clear();
}
public static void main(String[] args) {
int connectionsToGoogle = Integer.parseInt(args[0]);
int port = Integer.parseInt(args[1]);
NioReactor nio = NioReactor.create();
MapConfiguration config = new MapConfiguration();
config.add("connectionsToGoogle", connectionsToGoogle);
Server server = new AsyncHttpServer(nio, port, config);
server.open();
nio.start();
}
}
The advantages of the code above are:
- It is small and simple.
- It only uses one thread, the critical reactor thread, for all network activity.
- There is no multithreading programming, there is no blocking and there is no concurrent queues.
- It distributes the load across a set of connections to GoogleFinance (load balance).
- If one connection to GoogleFinance fails, it re-sends the pending requests on that connection to other connections (failover).
- You can scale the front-end to support a larger number of simultaneous clients and decrease latency by launching more http servers pinned to other cpu cores.
- You can scale the back-end to increase throughput by adding more connections to GoogleFinance (i.e.
connectionsToGoogleabove).
Asynchronous Messages
If you start to enjoy the idea of distributed systems, the next step is to dive into the world of true distributed systems based on asynchronous messages. Instead of making asynchronous network requests to a single node, messages are sent to the distributed system so any node can take action if necessary. And because asynchronous messages are usually implemented through a reliable UDP protocol, you are able to build a truly distributed system that provides: parallelism (nodes can truly run in parallel); tight integration (all nodes see the same messages in the same order); decoupling (nodes can evolve independently); failover/redundancy (when a node fails, another one can be running and building state to take over immediately); scalability/load balancing (just add more nodes); elasticity (nodes can lag during activity peaks without affecting the system as a whole); and resiliency (nodes can fail / stop working without taking the whole system down). For more information about how asynchronous messaging middlewares work you can check CoralSequencer.
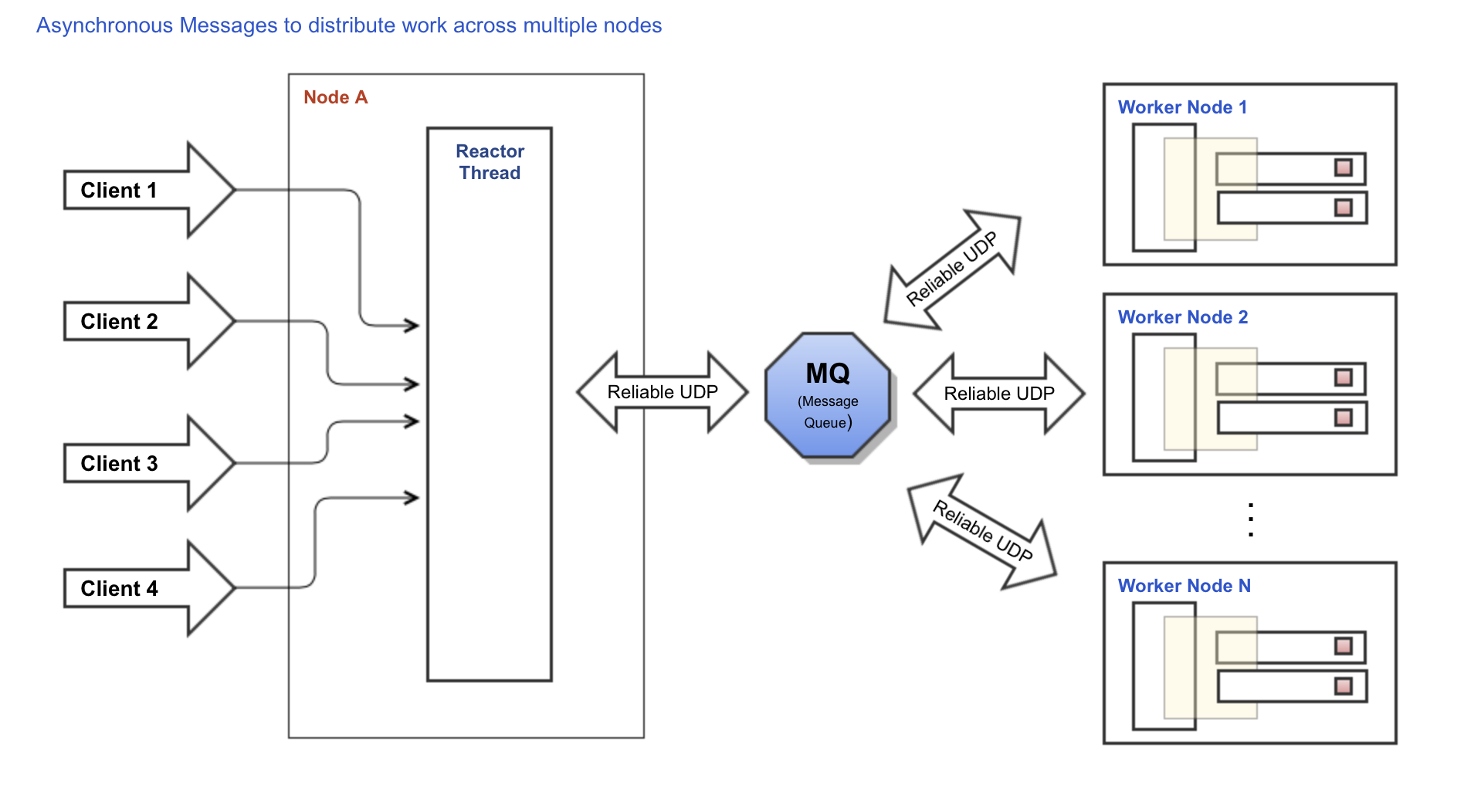
Conclusion
Every system will eventually have to perform some kind of action that requires an arbitrary amount of time to complete. In the past, pure multithreading applications became very popular, but the one-thread-per-request model does not scale. By using concurrent queues you can make a multithreaded system without all the multithreading complexity and best of all it can easily scale to thousands of simultaneous connections. But there is also an alternative solution: distributed systems where instead of using an in-memory concurrent queue to distribute work across threads you use the network to distribute work across nodes, making asynchronous network calls to these nodes. The next architectural step is to use an asynchronous messaging middleware (MQ) instead of network requests to design distributed systems that are not only easy to scale but are also loosely coupled providing parallelism, tight integration, failover, redundancy, load balancing, elasticity and resiliency.