You need a high throughput application capable of handling thousands of client connections simultaneously but some client requests might take long to process for whatever reason. How can that be done in an efficient way without impacting other connected clients and without leaving the application unresponsive for new client connections?
Solution
To handle thousands of connections an application must use non-blocking sockets over a single selector, which means the same thread will handle thousands of connections simultaneously. Problem is, if one of these connections lags for whatever reason, all other ones and the application as a whole must not be affected. In the past this problem was solved with the infamous one-thread-per-client approach which does not scale and leads to all kinds of multithreading pitfalls like race conditions, visibility issues and deadlocks. By using one thread for the selector and a fixed number of threads for the heavy-duty work, a system can solve this problem by distributing client work (and not client requests) among the heavy-duty threads without affecting the overall performance of the application. But how does this communication between the selector thread and the heavy-duty threads happen? Through CoralQueue demultiplexers and multiplexers.
Diagram
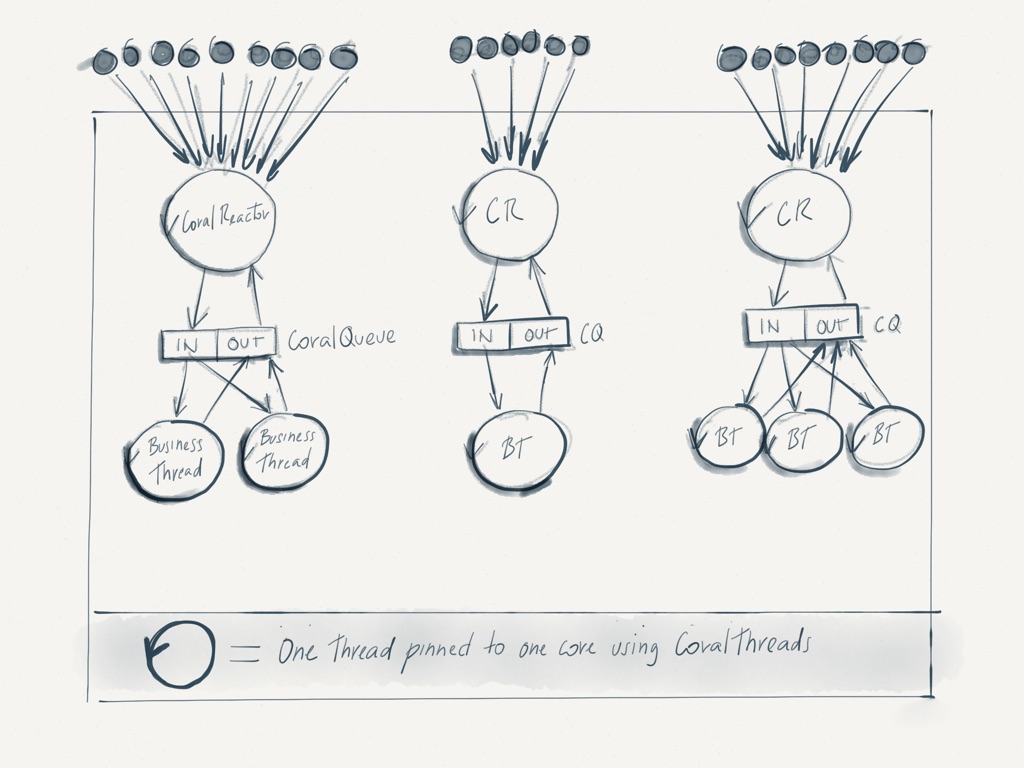
Flow
- CoralReactor running on single thread pinned to an isolated cpu core with CoralThreads.
- CoralReactor opens one or more servers listening on a local port. All servers are running on the same reactor thread.
- A server can receive one or thousands of connections from many clients across the globe.
- Each client sends requests with some work to be performed.
- The server does not perform this work. Instead it passes a message describing the work to a heavy-duty thread using a CoralQueue demultiplexer.
- The CoralQueue demux distributes the messages among the heavy-duty threads.
- The heavy-duty threads are also pinned to an isolated cpu core with CoralThreads.
- A heavy-duty thread executes the work and sends back a message with the results to the server using a CoralQueue multiplexer.
- The server picks up the message from the CoralQueue mux and reports back the results to the client.
FAQ
- Won’t you have to create garbage when passing messages back and forth among threads?
A: No. CoralQueues is a ultra-low-latency, lock-free data-structure for inter-thread communication that does not produce any garbage. - What happens if the queue gets full?
A: A full queue will cause the reactor thread to block waiting for space. This creates latencies. To avoid a full queue you can start by increasing the number of heavy-duty threads and/or increasing the size of the queue. - I did number 2 above but I am still getting a full queue. Now what?
A: CoralQueue has the built-in feature to write messages to disk asynchronously when it hits a full queue so it does not have to block waiting for space. Then the heavy-duty threads can get the messages from the queue file when they don’t find them in memory. You can use this approach not to disturb the reactor thread but at this point it is probably a good idea to also try to make whatever work your heavy-duty threads are performing more efficient. - How many connections can the application handle?
A: CoralReactor can easily handle 10k+ connections concurrently in a single thread. If your machine has additional cores, you can also add more reactor threads to increase this number even more. - How many heavy-duty threads should I have?
A: That depends on the number of available cpu cores that your machine has. A cpu core is a scarce resource so you should allocate them across your applications wisely. Creating more threads than the number of available cpu cores won’t bring any benefit and it will actually degrade the performance of the system due to context switches. Ideally you should have a fixed number of heavy-duty threads pinned to their own isolated core so they are never interrupted.
Variations
Instead of using one CoralQueue demultiplexer to randomly distribute messages across all heavy-duty threads, you can introduce the concept of lanes, with each lane having a heaviness number attached to it. For example, heavy tasks go all to lane 1, not-so-heavy tasks go to lane 2 and light tasks go to lane 3. The application would then decide in which lane a message should be dispatched. If a lane will be processed by a single heavy-duty thread, it can use a regular one-producer-to-one-consumer CoralQueue queue. If a lane will be served by 2 or more heavy-duty threads, then it can use a CoralQueue demultiplexer. To report back the results to the server, all heavy-duty threads can continue to use a CoralQueue multiplexer.
Code Example
Below you can see a simple server illustrating the architecture described above. To keep it simple it receives a string (the request) and returns the string prepended by its length (the response). It supports many clients and distribute the work among worker threads using a demux. Then it uses a mux to collect the results from the worker threads and respond to the appropriate client. In a more realistic scenario, the worker threads would be doing some heavier work, like accessing a database. You can easily test this server by connecting through a telnet client.
package com.coralblocks.coralreactor.client.bench.queued;
import java.nio.ByteBuffer;
import com.coralblocks.coralbits.util.Builder;
import com.coralblocks.coralbits.util.ByteBufferUtils;
import com.coralblocks.coralqueue.demux.AtomicDemux;
import com.coralblocks.coralqueue.demux.Demux;
import com.coralblocks.coralqueue.mux.AtomicMux;
import com.coralblocks.coralqueue.mux.Mux;
import com.coralblocks.coralreactor.client.Client;
import com.coralblocks.coralreactor.nio.NioReactor;
import com.coralblocks.coralreactor.server.AbstractLineTcpServer;
import com.coralblocks.coralreactor.server.Server;
import com.coralblocks.coralreactor.util.Configuration;
import com.coralblocks.coralreactor.util.MapConfiguration;
public class QueuedTcpServer extends AbstractLineTcpServer {
static class WorkerRequestMessage {
long clientId;
ByteBuffer buffer;
WorkerRequestMessage(int maxRequestLength) {
this.clientId = -1;
this.buffer = ByteBuffer.allocateDirect(maxRequestLength);
}
void readFrom(ByteBuffer src) {
buffer.clear();
buffer.put(src);
buffer.flip();
}
}
static class WorkerResponseMessage {
long clientId;
ByteBuffer buffer;
WorkerResponseMessage(int maxResponseLength) {
this.clientId = -1;
this.buffer = ByteBuffer.allocateDirect(maxResponseLength);
}
}
private final int numberOfWorkerThreads;
private final Demux<WorkerRequestMessage> demux;
private final Mux<WorkerResponseMessage> mux;
private final WorkerThread[] workerThreads;
public QueuedTcpServer(NioReactor nio, int port, Configuration config) {
super(nio, port, config);
this.numberOfWorkerThreads = config.getInt("numberOfWorkerThreads");
final int maxRequestLength = config.getInt("maxRequestLength", 256);
final int maxResponseLength = config.getInt("maxResponseLength", 256);
Builder<WorkerRequestMessage> requestBuilder = new Builder<WorkerRequestMessage>() {
@Override
public WorkerRequestMessage newInstance() {
return new WorkerRequestMessage(maxRequestLength);
}
};
this.demux = new AtomicDemux<WorkerRequestMessage>(1024, requestBuilder, numberOfWorkerThreads);
Builder<WorkerResponseMessage> responseBuilder = new Builder<WorkerResponseMessage>() {
@Override
public WorkerResponseMessage newInstance() {
return new WorkerResponseMessage(maxResponseLength);
}
};
this.mux = new AtomicMux<WorkerResponseMessage>(1024, responseBuilder, numberOfWorkerThreads);
this.workerThreads = new WorkerThread[numberOfWorkerThreads];
}
@Override
public void open() {
for(int i = 0; i < numberOfWorkerThreads; i++) {
if (workerThreads[i] != null) {
try {
// make sure it is dead!
workerThreads[i].stopMe();
workerThreads[i].join();
} catch(Exception e) {
throw new RuntimeException(e);
}
}
}
mux.clear();
demux.clear();
for(int i = 0; i < numberOfWorkerThreads; i++) {
workerThreads[i] = new WorkerThread(i);
workerThreads[i].start();
}
nio.addCallback(this); // we want to constantly receive callbacks from
// reactor thread on handleCallback() to drain responses from mux
super.open();
}
@Override
public void close() {
for(int i = 0; i < numberOfWorkerThreads; i++) {
if (workerThreads[i] != null) {
workerThreads[i].stopMe();
}
}
nio.removeCallback(this);
super.close();
}
@Override
protected void handleMessage(Client client, ByteBuffer msg) {
if (ByteBufferUtils.equals(msg, "bye") || ByteBufferUtils.equals(msg, "exit")) {
client.close();
return;
}
// on a new message, dispatch to the demux so worker threads can process it:
WorkerRequestMessage req;
while((req = demux.nextToDispatch()) == null); // busy spin...
req.clientId = getClientId(client);
req.readFrom(msg);
demux.flush();
}
class WorkerThread extends Thread {
private final int index;
private volatile boolean running = true;
public WorkerThread(int index) {
super("WorkerThread-" + index);
this.index = index;
}
public void stopMe() {
running = false;
}
@Override
public void run() {
while(running) {
// read from demux and process:
long avail = demux.availableToPoll(index);
if (avail > 0) {
for(int i = 0; i < avail; i++) {
// get the request:
WorkerRequestMessage req = demux.poll(index);
// do something heavy with the request, like accessing database or big data...
// for our example we just prepend the message length
long clientId = req.clientId;
int msgLen = req.buffer.remaining();
// get a response object from mux:
WorkerResponseMessage res = null;
while((res = mux.nextToDispatch(index)) == null); // busy spin
// notice below that we are just copying data from request to response:
res.clientId = clientId; // copy clientId
res.buffer.clear();
ByteBufferUtils.appendInt(res.buffer, msgLen);
res.buffer.put((byte) ':');
res.buffer.put((byte) ' ');
res.buffer.put(req.buffer); // copy buffer contents
res.buffer.flip(); // don't forget
}
mux.flush(index);
demux.donePolling(index);
nio.wakeup(); // don't forget so handleCallback is called
}
}
}
}
@Override
protected void handleCallback(long nowInMillis) {
// this is the reactor thread calling us back to check whether the mux has pending results:
long avail = mux.availableToPoll();
if (avail > 0) {
for(long i = 0; i < avail; i++) {
WorkerResponseMessage res = mux.poll();
Client client = getClient(res.clientId);
if (client != null) { // client might have disconnected...
client.send(res.buffer);
}
}
mux.donePolling();
}
}
public static void main(String[] args) {
NioReactor nio = NioReactor.create();
MapConfiguration config = new MapConfiguration();
config.add("numberOfWorkerThreads", 4);
Server server = new QueuedTcpServer(nio, 45451, config);
server.open();
nio.start();
}
}